Google Ngram Viewer es un motor de búsqueda que muestra las frecuencias de un conjunto de cadenas de búsqueda delimitadas por comas, utilizando un recuento anual de n-gramas de fuentes impresas entre 1500 y 2008. Liberado en 2010, la fuente principal de donde se nutre este programa es Google Books. El programa puede buscar una sola palabra, un conjunto de ellas o frases completas, incluyendo errores ortográficos. Esto permitiría a historiadores y lingüistas trazar la trayectoria de palabras y frases a través del tiempo sobre la base de una enorme cantidad de datos lo que permite observar el auge y la caída de ciertas expresiones, giros y palabras. Incluso algunos historiadores denominaron a este nuevo campo abierto por Google como culturomics. Sin embargo, aunque el fondo puede llegar a ser interesante, el Ngram Viewer dispone de varios problemas.
El más evidente son los errores en el reconocimiento de caracteres, que nunca es un proceso perfecto y que empeora cuando las tipografías utilizadas son antiguas. Uno de los mejores ejemplos, es la confusión que tiene el sistema con las letras f y s. El segundo es que existe una preponderancia de literatura científica. El tercero los errores en la introducción de los metadatos de los libros escaneados que pueden dar representaciones de términos en épocas que no existían.
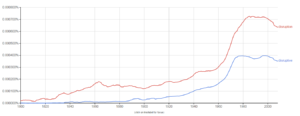
En el gráfico siguiente, podemos ver la evolución comparativa de los términos disruptive y disruption a modo de ejemplo.